Pembuatan Program Wordcount pada Hadoop menggunakan Java
1. Jalankan Hadoop
start-dfs.sh
start-yarn.sh
2. Buat folder input2
hadoop fs -mkdir /input2

3. Buat file inputWordCount.txt di komputer lokal, lalu isi file tersebut dengan kata-kata tertentu
sudo nano inputWordCount.txt

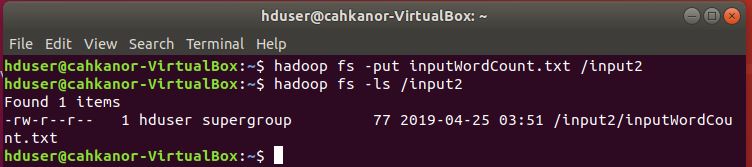
4. Pindah file inputWordCount.txt dari komputer lokal ke folder input2 pada HDFS
hadoop fs -put inputWordCount.txt /input2
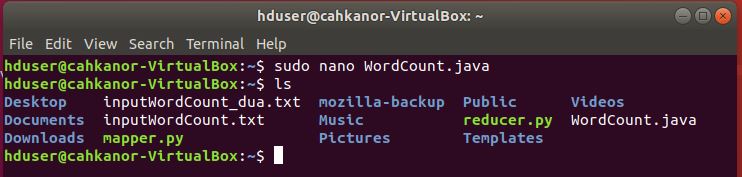
5. Buat kode program untuk wordcount dan simpan dengan nama WordCount.java
sudo nano WordCount.java
Berikut ini adalah contoh kode program untuk wordcount menggunakan Java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { // Map function public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // Splitting the line on spaces String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.write(word, new IntWritable(1)); } } } // Reduce function public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "WC"); job.setJarByClass(WordCount.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
Seluruh program MapReduce secara fundamental dapat dibagi menjadi tiga bagian:
a. Mapper Phase Code
b. Reducer Phase Code
c. Driver Code
Mapper Code:
1 2 3 4 5 6 7 8 9 10 11 12 |
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // Splitting the line on spaces String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.write(word, new IntWritable(1)); } } } |
- Class MyMapper mengextend class Mapper yang sudah didefinisikan dalam Kerangka MapReduce.
- Input dan output dari Mapper adalah pasangan key/value
- Input:
- key adalah offset dari masing-maing baris pada file teks: LongWritable
- value adalah teks pada masing-masing baris: Text
- Output:
- key adalah kata-kata yang sudah ditokenisasi/dipisah-pisah: Text
- Kita punya hardcoded value pada kasus ini yaitu 1: IntWritable
- Sekarang kita sudah menuliskan sebuah kode dalam bahasa java untuk melakukan tokenisasi kata-kata dan memberikan nilai 1.
Reducer Code:
1 2 3 4 5 6 7 8 9 10 11 12 |
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } |
- Class MyReducer mengextend class Reducer yang sudah didefinisikan dalam Kerangka MapReduce.
- Input dan output dari Reducer adalah pasangan key/value
- Input:
- key adalah kata-kata unik yang telah digenerate setelah fase sorting dan shuffling: Text
- value adalah daftar integer yang berkorespondensi ke masing-masing key: IntWritable
- key adalah kata-kata unik yang telah digenerate setelah fase sorting dan shuffling: Text
- Output:
- key adalah kata-kata unik yang ada pada file: Text
- value adalah jumlah kemunculan masing-maing kata unik: IntWritable
- Sekarang kita sudah menuliskan sebuah kode dalam bahasa java melakukan agregasi nilai-nilai yang ada pada daftar integer yang berkorespondensi ke masing-masing key lalu menghasilkan jawaban akhir perhitungan.
Driver Code:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "WC"); job.setJarByClass(WordCount.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } |
- Pada Class driver, kita lakukan pengaturan konfigurasi pekerjaan MapReduce untuk dijalankan di Hadoop.
- Kita tentukan nama pekerjaan (job), tipe data input / output mapper dan reducer.
- Kita juga tentukan nama-nama Class mapper dan reducer.
- Path folder input dan output juga ditentukan.
- Fungsi setInputFormatClass() digunakan untuk menentukan bagaimana Mapper akan membaca input data. Di sini, kita pilih TextInputFormat sehingga satu baris kata dari file teks input dibaca oleh mapper sekaligus dalam satu waktu .
- Fungsi main() adalah fungsi utamanya. Dalam metode ini, kita buat instance objek Konfigurasi baru untuk pekerjaan tersebut.
6. Export classpath
export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
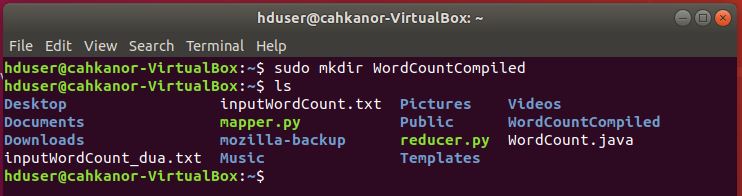
7. Buat folder WordCountCompiled untuk menympan hasil compile file WordCount.java
sudo mkdir WordCountCompiled
8. Ubah permission dari folder yang akan dipakai untuk menympan hasil compile
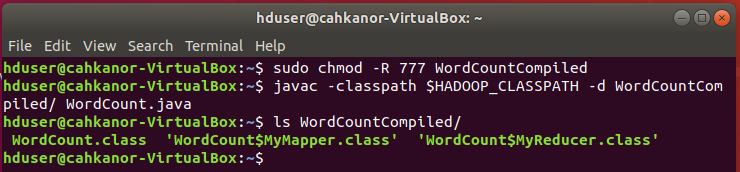
sudo chmod -R 777 WordCountCompiled
9. Compile file WordCount.java yang telah dibuat
javac -classpath $HADOOP_CLASSPATH -d WordCountCompiled/ WordCount.java
10. Hasil compile bisa dilihat pada folder WordCountCompiled
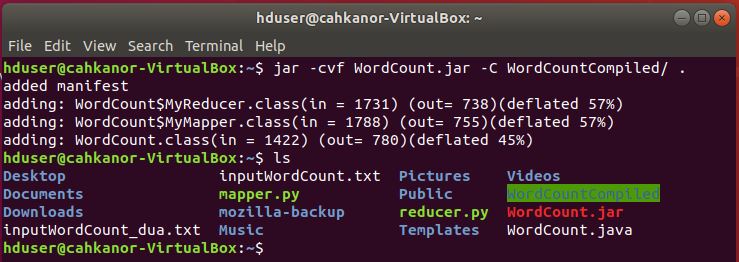
11. Ubah menjadi file executable .jar
jar -cvf WordCount.jar -C WordCountCompiled/ .
12. Jalankan file jar tersebut untuk menghitung jumlah kata pada file inputWordCount.txt yang ada di folder input2 pada HDFS, kemudian simpan hasilnya di folder WordCount-Result
hadoop jar WordCount.jar WordCount /input/inputWordCount.txt /WordCount-Result
Cek di folder WordCount-Result:
hadoop fs -ls WordCount-Result
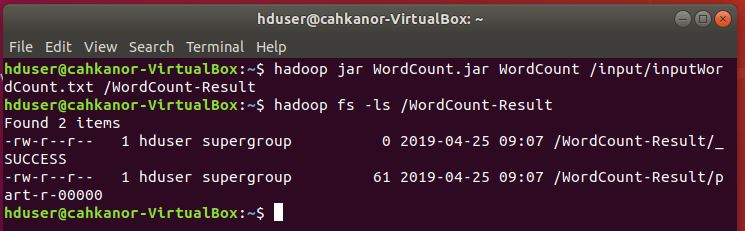
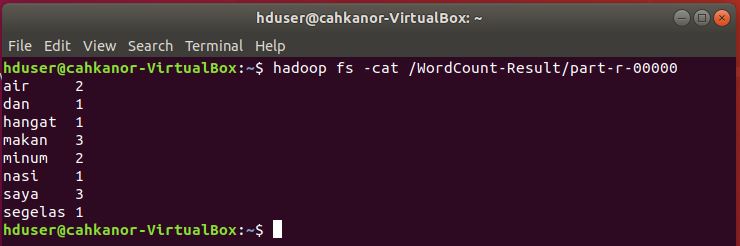
Pada folder WordCount-Result terdapat dua file seperti gambar di atas. Hasil perhitungan bisa dilihat pada file yang nama depannya part, pada kasus ini part-r-00000.
13. Melihat hasil perhitungan Wordcount di file part-r-00000
hadoop fs -cat /WordCount-Result/part-r-00000