Pembuatan Program Wordcount pada Hadoop menggunakan Python
Meskipun kerangka kerja Hadoop ditulis dalam bahasa Java, program untuk Hadoop tidak harus dikodekan di Java, tetapi juga dapat dikembangkan dalam bahasa lain seperti Python atau C ++ (C++ sejak versi 0.14.1).
“Trik”nya untuk menjalankan kode Python pada Hadoop adalah menggunakan Hadoop Streaming API untuk membantu mengirimkan data antara Mapper dan Reducer melalui STDIN (input standar) dan STDOUT (output standar). Kita akan menggunakan sys.stdin Python untuk membaca input data dan mencetak output ke sys.stdout.
1. Jalankan Hadoop
start-dfs.sh
start-yarn.sh
2. Buat folder input2
hadoop fs -mkdir /input2

3. Buat file inputWordCount.txt di komputer lokal, lalu isi file tersebut dengan kata-kata tertentu
sudo nano inputWordCount.txt

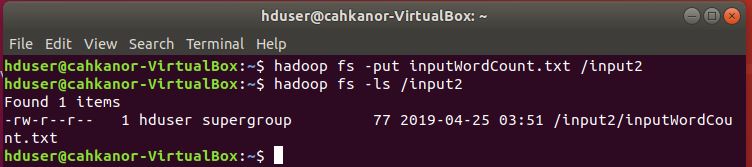
4. Pindah file inputWordCount.txt dari komputer lokal ke folder input2 pada HDFS
hadoop fs -put inputWordCount.txt /input2
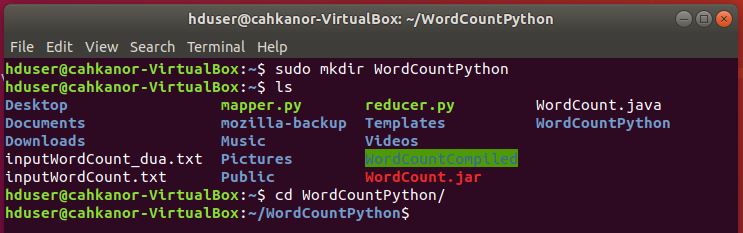
5. Buat foder WordCountPython sebagai tempat untuk menaruh file python.
sudo mkdir WordCountPython
6. Pindah ke folder WordCountPython
cd WordCountPython
7. Buat file Mapper.py
sudo nano Mapper.py
Berikut adalah contoh kodenya:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#!/usr/bin/env python """mapper.py""" import sys # input comes from STDIN (standard input) for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # split the line into words words = line.split() # increase counters for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py # # tab-delimited; the trivial word count is 1 print '%s\t%s' % (word, 1) |
8. Buat file Reducer.py
sudo nano Reducer.py
Berikut adalah contoh kodenya:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#!/usr/bin/env python """reducer.py""" from operator import itemgetter import sys current_word = None current_count = 0 word = None # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # parse the input we got from mapper.py word, count = line.split('\t', 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print '%s\t%s' % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print '%s\t%s' % (current_word, current_count) |
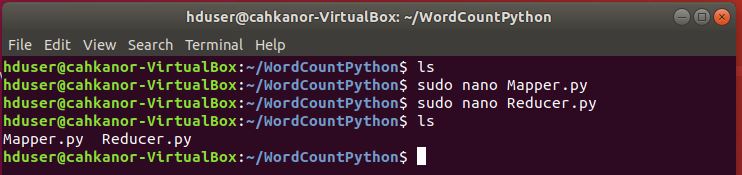
9.Pastikan file tersebut memiliki izin eksekusi.
sudo chmod +x Mapper.py
sudo chmod +x Reducer.py
10. Tes kode yang sudah kita buat di komputer lokal
a. Tes Mapper.py
echo “saya makan jagung bakar saya bakar bakar” | ~/WordCountPython/Mapper.py
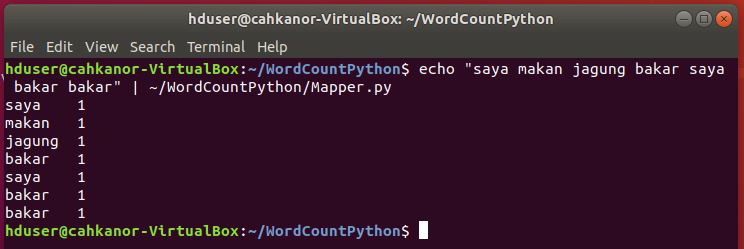
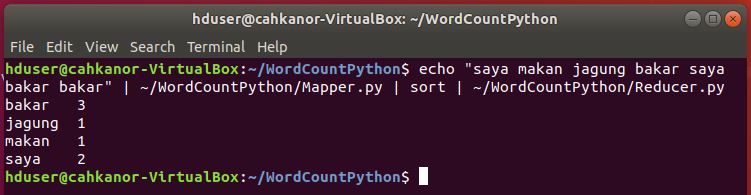
b. Tes Mapper dan Reducer
echo “saya makan jagung bakar saya bakar bakar” | ~/WordCountPython/Mapper.py | sort | ~/WordCountPython/Reducer.py
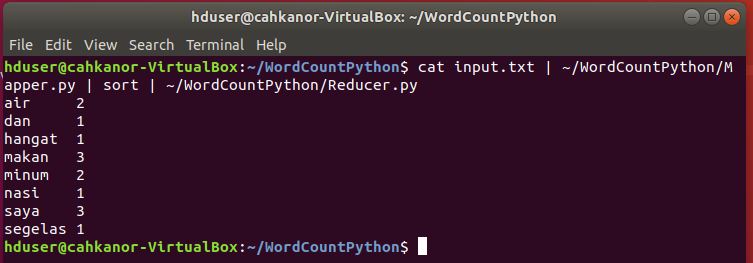
c. Tes Mapper dan Reducer dengan input file text
Buat file input.txt dan isi dengan kata-kata tertentu
sudo nano input.txt

Jalankan Mapper dan Reducer pada file input.txt
cat input.txt | ~/WordCountPython/Mapper.py | sort | ~/WordCountPython/Reducer.py
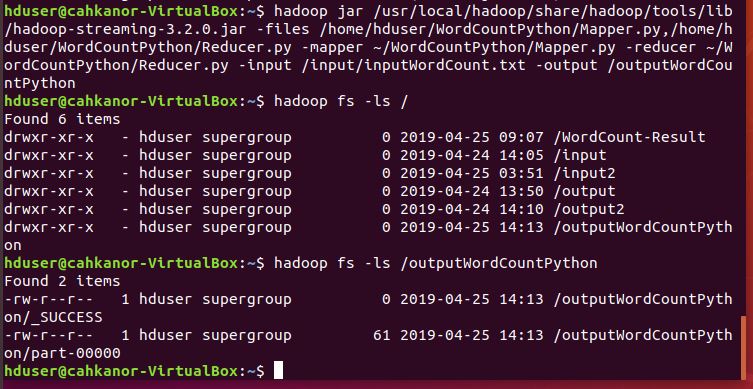
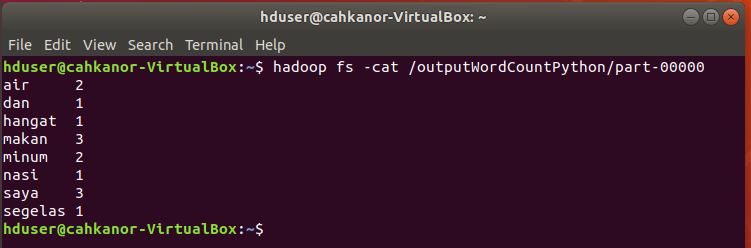
11. Selanjutnya akan kita jalankan pada Hadoop, kita gunakan untuk menghitung jumlah kata pada file inputWordCount.txt di folder input2
12. Pindah terlebih dahulu ke folder utama Hadoop
cd /usr/local/hadoop/
13. Jalankan program Mapper dan Reducer pada file file inputWordCount.txt di folder input2
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.2.0.jar -files /home/hduser/WordCountPython/Mapper.py,/home/hduser/WordCountPython/Reducer.py -mapper ~/WordCountPython/Mapper.py -reducer ~/WordCountPython/Reducer.py -input /input/inputWordCount.txt -output /outputWordCountPython